Solving Data Mining Challenges in Database Homework

Solving database assignments effectively requires a structured approach that covers multiple key concepts such as data modeling, rule-based classification, decision trees, clustering, and regression models. Whether you are working on predictive modeling, classification rules, or data analysis, following the right guidelines ensures accuracy and efficiency. If you ever find yourself struggling with complex database concepts, seeking database homework help can provide the support needed to excel in your coursework. This guide will walk you through essential strategies for tackling database assignments, from understanding the requirements to implementing the best problem-solving techniques. With the increasing importance of data-driven decision-making, mastering database assignments is crucial for academic and professional success. Additionally, if you need help with data mining homework, focusing on key topics like Naïve Bayes models, association rule mining, and clustering techniques can significantly improve your problem-solving abilities. By leveraging the right methodologies, using appropriate tools like MySQL, Python, or R, and following a step-by-step approach, you can confidently complete any database-related task. This guide provides comprehensive insights into solving database assignments efficiently, ensuring high-quality solutions that meet academic standards. From preparing the work environment to performing calculations, evaluating models, and validating results, every aspect is covered to help students achieve better grades. Whether you need to derive rules from a decision tree, perform entropy-based discretization, or compute performance metrics for a regression model, this guide will equip you with the necessary knowledge and skills. By understanding these concepts and practicing with real-world examples, students can enhance their analytical abilities and complete assignments with confidence. If you're looking for structured, expert guidance, this resource will help you navigate through your database assignments smoothly and effectively.

1. Understanding the Assignment Requirements
Before beginning a database assignment, carefully read all questions to understand the scope and required solutions. Identify the key topics involved, such as data mining, rule-based classification, and regression models. Recognizing the types of tasks—whether prediction, classification, or model evaluation—will help structure a precise and well-organized response. Breaking down complex requirements into smaller, manageable tasks will ensure accuracy and completeness in your solutions. Before attempting to solve the assignment, read through all the questions carefully. Identify:
- The key topics covered (e.g., data mining, security, decision trees, clustering, etc.).
- The types of tasks required (e.g., prediction, classification, rule derivation, or model evaluation).
- The expected deliverables (e.g., mathematical derivations, tables, graphs, or explanations).
2. Preparing Your Work Environment
Having the right tools is essential for effective problem-solving. Install and set up database management systems such as MySQL or PostgreSQL. Utilize programming tools like Python (Pandas, Scikit-learn) or R for data analysis and visualization. Keep statistical tools, textbooks, and online resources handy to aid in theoretical explanations. A well-prepared work environment enhances efficiency and accuracy in database assignments.
Ensure you have access to:
- A database management system (e.g., MySQL, PostgreSQL, MongoDB).
- Data analysis tools such as Python (Pandas, Scikit-learn) or R.
- Statistical tools for calculations like Excel or MATLAB.
- The necessary textbook or online resources for theoretical concepts.
3. Solving Prediction-Based Questions
Prediction tasks often involve applying mathematical models to forecast results. When using linear models, substitute the given values into the provided equation and perform the necessary calculations. For decision trees or rule-based models, carefully follow the logical conditions and compute outcomes step by step. Use tables and clear formatting to present results in a structured manner.
Linear Model Predictions
For assignments requiring predictions using a linear model (e.g., predicting sales based on given parameters), follow these steps:
- Identify the formula given (e.g., Sales = Season*20 + ProductType*5 + Reputation*10 - 10).
- Substitute the given values for each scenario.
- Perform calculations and validate results.
- Present answers in a clear tabular format.
Decision Tree and Rule-Based Predictions
Decision Tree and Rule-Based Predictions
- Follow the given conditions.
- Apply exceptions if any exist.
- Compute values step by step.
- Use diagrams or tables to illustrate results clearly.
4. Handling Classification and Association Rules
Classification and association rules require identifying patterns in datasets. Compute support, confidence, and accuracy for rules by counting relevant data instances. When using the Naïve Bayes model, determine prior and conditional probabilities, then apply Bayes’ theorem to predict outcomes. Organizing results systematically will ensure clarity in presenting your findings.
Support, Confidence, and Accuracy Calculations
- Identify the rule structure (e.g., ACTION = STRETCH AND AGE = CHILD ==> RESULT = F).
- Count instances that satisfy the rule conditions.
- Compute:
- Support = (Number of instances matching the rule) / (Total instances).
- Confidence = (Correct predictions using rule) / (Total rule occurrences).
- Accuracy = (Correct predictions) / (Total data points).
Naïve Bayes Model
- Compute prior probabilities for each class.
- Compute conditional probabilities for attributes.
- Use Bayes’ theorem to predict the class of new data points.
5. Decision Trees and Attribute Selection
Building a decision tree requires choosing the most informative attribute as the root node. Compute the information gain for each attribute and select the one with the highest value. Continue the process recursively for child nodes. Graphical representation and step-by-step explanations can make decision tree solutions more comprehensible and effective.
Choosing the Root Node
- Compute Information Gain for all attributes.
- Choose the attribute with the highest information gain as the root.
- Repeat for subsequent nodes.
- Use entropy calculations where needed.
6. Regression Analysis and Model Evaluation
Regression analysis helps predict numerical outcomes based on input features. Compute Root Mean Squared Error (RMSE) to measure prediction accuracy and use correlation coefficients to assess relationships between variables. Evaluating the regression model thoroughly ensures that predictions align with real-world data trends.
Evaluating Linear Regression Models
- Compute Root Mean Squared Error (RMSE): RMSE
- Compute the Correlation Coefficient:
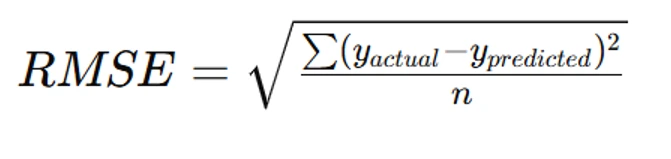
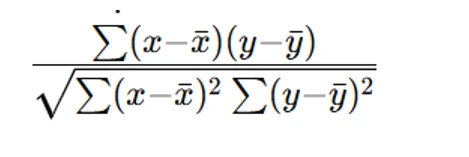
7. Clustering and Distance Calculations
Clustering involves grouping similar data points based on specific attributes. Compute the centroid of each cluster by averaging attribute values. To measure similarity between clusters, use single-linkage or complete-linkage distance calculations. Visualizing clusters through graphs or tables enhances understanding of relationships between data points.
Centroid Calculation
- Compute the mean of each attribute in a cluster.
- Represent clusters using their centroids.
Single-Linkage Distance Calculation
- Identify the closest points between two clusters.
- Compute Euclidean distance:
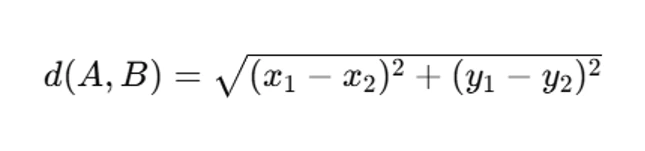
8. Rule Pruning and Association Rule Mining
Pruning improves rule accuracy and efficiency by eliminating weak rules. Calculate support and accuracy for given association rules, then adjust them to maintain a balance between coverage and precision. Ensure that each rule has a minimum of 75% accuracy while maintaining relevance to the dataset.
- Determine support and accuracy for association rules.
- Prune rules that have low support or accuracy.
- Ensure each rule has at least a 75% accuracy.
9. Data Discretization and Encoding
Converting numerical attributes into categorical values simplifies model training. Use equal-frequency binning to create bins with an equal number of data points or equal-width binning to segment data into fixed intervals. For categorical attributes, apply one-hot encoding or nested dichotomy methods to convert them into numerical representations.
Equal-Frequency and Equal-Width Binning
- Divide data into equal-sized bins (equal frequency) or fixed-width intervals (equal width).
- Assign bin labels accordingly.
Transforming Categorical Data
- Convert categorical attributes like Color and Size into numerical representations.
- Use one-hot encoding or nested dichotomy methods for class vectors.
10. Model Validation and Performance Evaluation
Cross-validation ensures that machine learning models generalize well. Implement k-fold cross-validation to split data into training and test sets. Compute performance metrics such as precision, recall, and F1-score. Construct ROC and lift curves to evaluate classification model effectiveness, ensuring reliable predictions.
Cross-Validation
- Use 4-fold cross-validation to split data into training and test sets.
- Compute model accuracy on different test sets.
ROC Curve and Lift Curve Analysis
- Organize predicted probabilities into a table.
- Compute True Positive Rate (TPR) and False Positive Rate (FPR).
- Construct ROC and lift curves based on computed values.
Conclusion
Effectively solving database assignments requires a structured approach, from understanding requirements to implementing advanced analytical techniques. Utilizing the right tools, organizing data methodically, and applying problem-solving strategies will enhance efficiency and accuracy. By mastering prediction models, classification techniques, clustering methods, and performance evaluation, students can confidently tackle complex database assignments and achieve academic success.